(CIS8008) Data analysis assignment on predictive analysis, text mining, big data problems and artificial intelligence
Question
Task: In your data analysis assignmentcritically analyse organisational and societal problems using descriptive and predictive analysis and internal and external data sources to generate insight, create value and support evidence based decision making. Examine legal, ethical and privacy dilemmas that arise from the use of business intelligence, analytics and evidence based decisions making to comply with legal and regulatory requirement.
Answer
Task 1 Predictive Analytics Case Study
Task 1.1 Exploratory data analysis and date preparationfor the data analysis assignment
Data is the foundation of data science. An excellent model cannot be constructed without first having a thorough familiarity with the data being used in its creation. Building the training set may take up to 80 percent of the effort in data science and data munging (wrangling, mashing, etc.), with the remaining 20 percent dedicated to developing the actual models. While specific knowledge in the field is essential, knowing what goals one may want to achieve is just vital for the data analysis assignment. A considerable amount of time is required for data investigation. Furthermore, one must consider the issue being solved, collect the appropriate data, and then examine it in the data analysis assignment.
Though horizontal and vertical scrolling may be manageable for a tiny dataset, a realistic data set size may include as many as a million rows. There is no way to recall or record every single missing value for the data analysis assignment. RapidMiner's Statistics window is a useful tool for tackling this challenge. The Statistics view is quite useful and resembles the "summary" or "head" function that programmers in Python or R would use to summarise data. RapidMiner streamlines and improves this process by making it very graphical and quick. Figure 1 displays the data set's statistical overview.
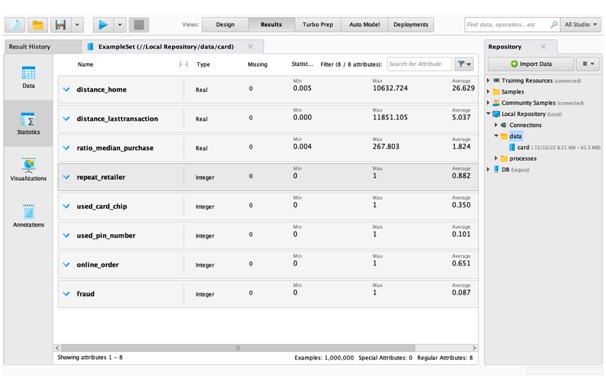
Figure 1: Data Summary
In the abridged version of the data analysis assignment, it can see the names of all the columns, the types of those columns, a missing column, and some statistics. This viewpoint provides a new way of looking at the information. The chosen dataset has 8 variables including the target variables. From figure 1, it can be said that there is no missing data. Further, all variables are numerical in nature with distance_home, distance_lasttransaction and ratio_median_purchase as real numbers and rest are integer, in specific binary variables. Therefore, it is necessary to understand the distributions of all three real variables prior to proceed to the next step of analysis.
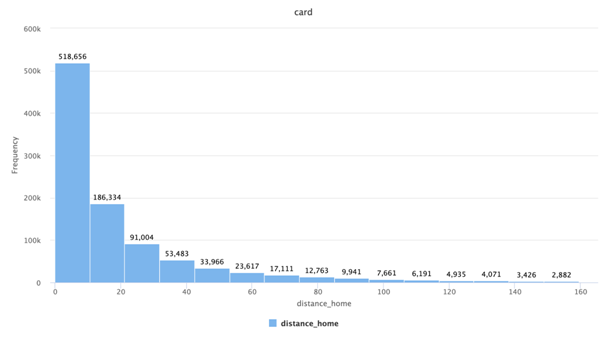
Figure 2: Histogram of data_home variable
Figure 2 in the data analysis assignmentis showing the distribution of data_home variable. From this histogram, it is clear that it follows right skewed distribution.
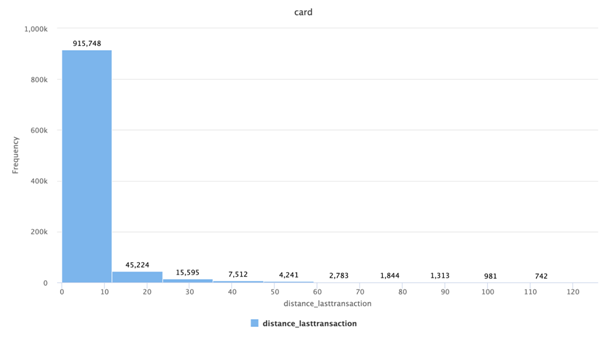
Figure 3: Histogram of distance_lasttransaction variable
Similar to above variable, this distance_lasttransaction variable is also following a right skewed distribution.
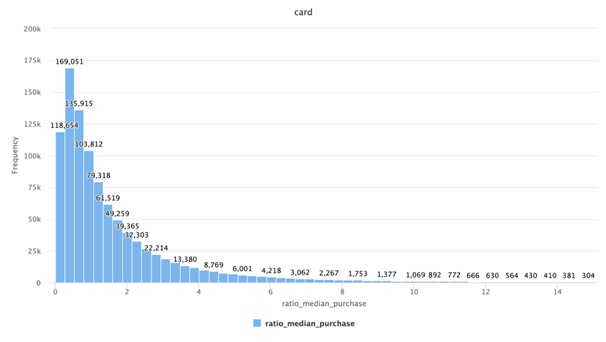
Figure 4: Histogram of ratio_median_purchase variable
Finally, the histogram of ratio_median_purchasein thedata analysis assignmentis indicating a left skewed distribution.
Thus, it can be said that all three variables are left skewed. Now, the next step is to understand how each of the variable is associated with target variable, “fraud”. The correlation matrix operator is used to get the correlation matrix. According to this matrix output, it can be said that distance_home, distance_lasttransaction, ratio_median_purchase and order_online are positively correlated with fraud variable. On the other hand, repeat_retailer, used_card_chip, and used_pin_number are negatively correlated with fraud variable. Now, if the correlation value is taken into consideration in the data analysis assignment, then it can be seen that ratio_mdeian_purchase has the highest correlation value and on the other hand, repeat_retailer has almost zero correlation. Therefore, according to the order of importance, the variables are ratio_median_purchase, online_order, distance_home, used_pin_number, distance_lasttransaction, used_card_chip, and repeat_retailer. At this moment, the dataset is ready for further analysis.
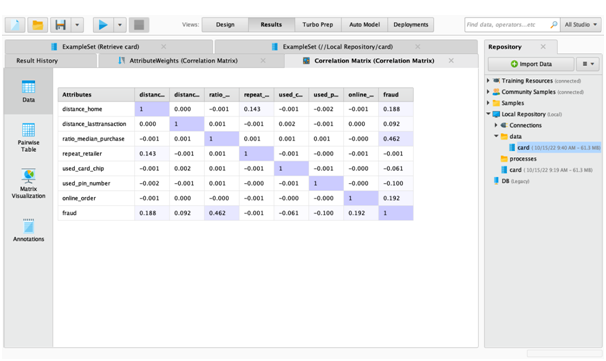
Figure 5: Correlation Table
Task 1.2 Decision Tree Model
The decision tree model operator in the data analysis assignmentis used in order to find out how these predictor variables predicts whether a credit card transaction is likely to be fraudulent or not based on the card.csv dataset. Figure 6 is showing the process.
Figure 6: Final Decision Tree Model Process
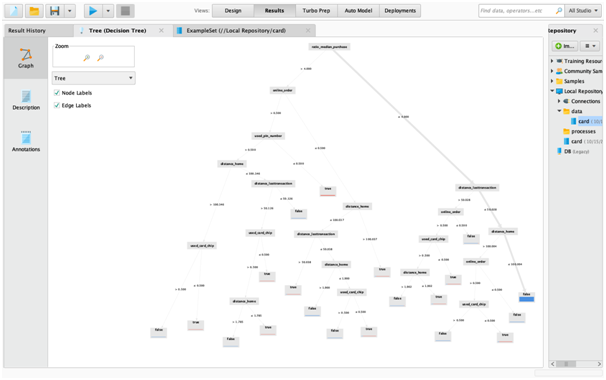
Figure 7: Final Decision Tree Model Output
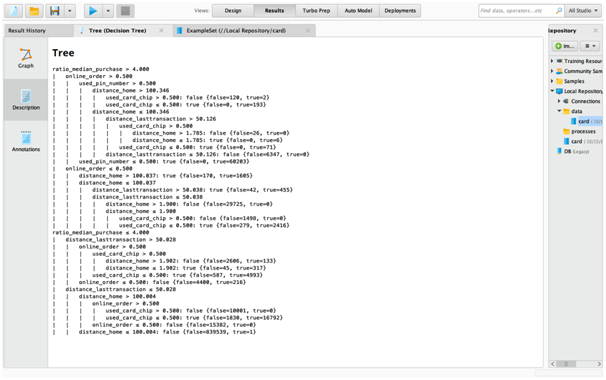
Figure 8: Final Decision Tree Model Rule
Figure 7 and 8 in the data analysis assignmentis showing outcome of the decision tree developed in this stage. From these, two output, it can be said that ratio_median_purchase plays key role in deciding whether the transaction would be a fraudulent or not. In fact, the decision tree outcome is clearly showing how each variable is playing their role in deciding fraudulent activity.
Task 1.3 Logistic Regression Model
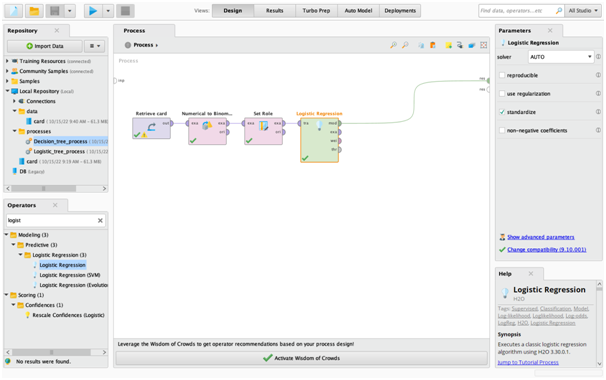
Figure 9: Final Logistic Regression Model Process
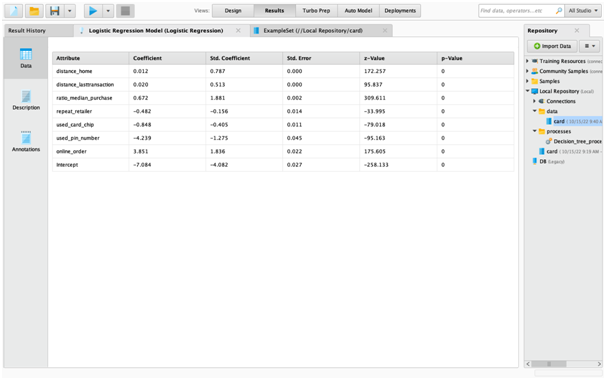
Figure 10: Final Logistic Regression Model Output
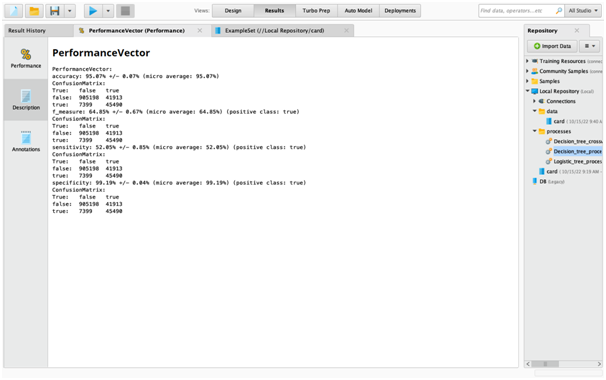
The logistic regression output as shown in the data analysis assignment indicates that the model is overall significant at 95% confidence level as the p value is less than 0.05. Further, the output is also showing that p value of each variable is also below 0.05. Hence, individually, each variable is also significant predictor of fraud variable. The logistic regression equation can be written as:
|
Parameters |
Decision Tree |
Logistic Regression |
|
Accuracy |
99.67% +/- 0.02% |
95.07% +/- 0.07% |
|
Sensitivity |
99.63% +/- 0.15% |
52.05% +/- 0.85% |
|
Specificity |
99.68% +/- 0.02% |
99.19% +/- 0.04% |
|
F measures |
98.15% +/- 0.14% |
64.85% +/- 0.67% |
Table 1: Comparison Table
The above table in the data analysis assignmentis showing that decision tree is a better model compare to logistic regression. Specific the vast variety of algorithms, it might be difficult to choose which one to use for a given Machine Learning assignment. It's not always easy to tell which strategy is better since it may perform better on certain tasks but constantly underperform on others. When comparing Logistic Regression with trees, one key distinction is in how the decision boundaries (i.e., the dividing lines) between classes are generated.
Task 2 Text mining and text analyticsin the data analysis assignment
Task 2.1 Concept Text mining and how text mining is related to text analytics
To get familiar with text mining, which refers to the activity of examining enormous volumes of textual resources in order to identify essential themes, patterns, and hidden links. Text mining, also known as text data mining, is the process of converting unstructured text into a structured format in order to find relevant patterns and fresh insights. This method as per the data analysis assignmentis also known as text data mining. Companies are able to investigate and identify hidden links within their unstructured data when they employ sophisticated analytical approaches such as Naive Bayes, Support Vector Machines (SVM), and other deep learning algorithms.
Text mining is a method as per the data analysis assignmentthat involves deducing information from unstructured text data using a series of actions that are included in the process. Text pre-processing is the procedure of cleaning and translating text data into a format that can be used, and it is required before one can go on to using the many text mining methods that are available. This methodology is an essential element of natural language processing (NLP), and it often entails the use of processes such as language identification, tokenization, part-of-speech tagging, chunking, and syntax parsing in order to suitably arrange data for analysis. After the text has been pre-processed to your satisfaction, you will be able to apply text mining algorithms to the data in order to get insights.
Text mining and text analytics are often used interchangeably in conversation or in data analysis assignment, but each phrase may also have a more nuanced sense of what it means to refer to itself. The processes of text mining and text analysis include the use of machine learning, statistics, and linguistics in order to recognise textual patterns and trends that exist within unstructured data. Text analytics allows for the discovery of deeper, more quantitative insights by mining and analysing existing textual content in order to convert the data into a more organised manner. After that, several strategies for data visualisation may be used to present the results to a larger audience.
Task 2.2 Real world application of text analytics
Stipulating text mining apps to drive data-driven choice like preventing cyber-crime is a great real-world illustration of text analytics' practical use for data analysis assignment. Most businesses today collect and retain vast volumes of information, and this data is expanding at an exponential pace. Companies using outdated methods will struggle to process this volume of data. Text mining has been more popular in recent years due to its ability to transform raw text input into useful information. Text mining, also known as text analytics, is the practise of automatically processing data and generating useful insights using a variety of artificial intelligence technologies to support data-driven decision making in businesses. Data mining, statistics, machine learning, information retrieval, and computational linguistics are just few of the many disciplines that make up text mining.
From a macro perspective for the data analysis assignment, 1.5 million cyber assaults every year may not seem like much, but broken down into smaller chunks, that's 4000 attacks per day or around 200 per hour. While some of these occurrences may be inconsequential or minor, others, such as the cyber-attack that hit major market participants last Friday and cost them millions of dollars, may have a devastating impact.
Our investigations in the data analysis assignmentled us to the conclusion that not much is being done to curb cybercrime. The industry has mostly ignored social media analytics and text mining for cyber-attack forensic, and hardly no firm is putting this technology to use to protect enterprises from cyber-attacks.
According to the data mentioned in the data analysis assignment, hackers trade information and cyberattack tools through bot networks on online dark markets, also known as social media forums and networks. In other words, the information is not hidden; nevertheless, there is just too much of it to process manually.
Latent Dirichlet Allocation (LDA) is an algorithm used in natural language processing that classifies sentences based on the subjects they discuss. According to this model considered in the data analysis assignment, every piece of written content may be broken down into a collection of distinct subjects, each of which has a collection of individual words with their own probability distributions.
To provide the likelihood of each word appearing in the text, Latent Dirichlet Allocation needs a massive quantity of annotated data. Therefore, it will be challenging for the model to produce correct predictions and, therefore, achieve success in forecasting cybercrime if you do not have.
This approach relies on probability, some of which may not be accurate, and is therefore difficult for the typical user to implement. We may, however, have more luck with our data analysis if we use a linguistic perspective. Why?
To evaluate text and pull out the most important ideas for the data analysis assignment, Bitext developed an in-house language-agnostic lexical analyzer and a PDA-based non-deterministic GLR parser.
The question now is how to do this. Syntactic analysis has been used. Phrases indicating nouns, verbs, adjectives, and others may be picked out. You'll need to study linguistics in order to do this. In order to glean useful information, you need to comprehend the context of each statement.
Stemming or lemmatization is an additional method used to improve outcomes. Is there a specific goal we may strive towards by using it? For instance, we may reduce "hacked," "hacking," and so on, to just "hack."
As a result, if we utilise linguistics as a tool to find out what's going on in the data analysis assignment, it may assist you protect your firm from cyber assault. By understanding the likely outcomes and current trends in cyber-crime communities, one may better prepare the company to withstand an assault.
Task 3 Explaining Big Data Platforms, Deep learning, Text miningin the data analysis assignment
With today's information explosion, we are generating more data for the data analysis assignmentthan we can ever analyse in a single day. This is bolstered by the fact that we now use the Internet for even the most mundane tasks. The vast majority of these records are written prose. Most of them are disorganised and hard to find. As a result, Big Data Analytics includes substantial work with unstructured text data. Examining textual information via the lens of Big Data Analytics is the focus of this piece.
Structured data, in contrast to its unstructured counterpart, is arranged in a way that makes it simple to retrieve and use, which is very helpful for Big Data Analytics. It is of a predetermined length and format, and is presented in such a way as to make inclusion, search, and the like easy, natural, and unobtrusive; this is especially true in the case of relational databases, whose underlying engines give the key mechanism to all method of accessibility.
Unlike structured data, which has some degree of organisation, unstructured data is in a more raw state. Because of this, it's quite challenging to work with them or get useful information from them for the data analysis assignment. Analytics for Big Data need more time and money to handle. Unfortunately, a Big Data analyst is now faced with a far larger quantity of unstructured or semi-structured data. The textual information discovered by Big Data Analytics originates from several places and is stored in a variety of formats. Even if a paper is about a financial transaction or a bank statement, the information it contains is similar to scripted dialogue. Likewise, there is little to no hierarchy in the information that may be discovered in a log, tweet, or social media post. Most of them are not structured at all, and the ones that are usually poorly organised at best.
The meat and potatoes of text analytics is figuring out how to make sense of all those unstructured texts, reading them, analysing them, and pulling out the information that's really useful, then organising it in a way that can be used for additional analysis down the road. Many methods are used in text data analytics to accomplish this goal. Natural Language Processing (NLP), data mining, knowledge discovery, statistics, computational linguistics, and many more complementary technologies are all sources for these methods. There is not a single tried-and-true method or instrument that can be used for the data analysis assignment. As a matter of fact, everything that facilitates text analytics or affects its outcome may be considered a crucial component of the analysis. It is the method, not the tools or procedures, that is critical. Only a few of the many text analytics techniques are described here.
Although keyword searches are an element of text analytics, it's important to keep in mind that they're not the sole aspect. The distinction is very important. While in searches we employ keywords to get relevant information, the outcome is always known or predictable, the emphasis of text analytics is on extracting information without knowing what we may receive. Information discovery is at the heart of text analytics. As a result, analytics use search as a method for classifying documents and extracting a summary of their contents. Unstructured data as per the data analysis assignmentis typically mined using a mix of Natural Language Processing (NLP) and statistics. Natural language processing (NLP) has been a well-studied and intricate area for almost two decades, with the goal of extracting information of value from text. For a long time, computation linguistics has relied on grammatical structure and parts of speech to determine whether or not a given phrase is meaningful. This method is used in text analytics for classifying information.
Task 4 Artificial Intelligence: automation and augmentation in workplace and ethical considerations
Task 4.1 Humans and Artificial Intelligence considered for the data analysis assignment
Progress in artificial intelligence as per the data analysis assignmenthas allowed AI to emerge from the realm of science fiction and into the mainstream. Self-driving vehicles, intelligent virtual assistants, chatbots, and surgical robots are just a few examples of the many intelligent devices available today. A controversy has arisen between AI and HI as AI has become an established technology in today's business and a part of the average man's everyday existence.
The concern that AI would "replace" humans and eventually surpass them in intelligence is perhaps the most widespread. But it's not totally accurate either. While AI has come a long way, with computers being able to learn from their mistakes and make thoughtful judgments, it still relies heavily on human qualities like intuition to perform at its best. The goal of artificial intelligence as per the data analysis assignmentis to create computers that can replicate human behaviour and do human-like acts, whereas the goal of human intelligence is to adapt to new surroundings by leveraging a mix of diverse cognitive processes. Machines are digital whereas the human brain operates on an analogue level.
When it comes to AI, Together, AI and HI strive to deliver a more productive work style that facilitates the easy resolution of issues. It can find a solution to any issue in a flash, unlike human intelligence, which needs time to become used to new systems. Thus, to be certain in the data analysis assignment, the primary distinction between natural and artificial intelligence is the process of functioning and the time required for both. Machines powered by artificial intelligence (AI) depend on data and pre-programmed instructions, whereas humans make use of their brain's computational capability, memory, and ability to reason. Furthermore, people need a considerable amount of time to absorb the difficulties, evaluate their meaning, and adjust to them. Artificial intelligence systems are more likely to provide reliable outcomes if they are given correct training data and other relevant information. Understanding the significance of prior events and experiences is fundamental to what constitutes human intelligence. Lifelong trial and error is about gaining wisdom via experience. Human intelligence consists essentially of the capacity for intelligent cognition and intelligent action. Artificial Intelligence, on the other hand, is lacking in this area since robots lack the ability to reason. Accordingly in the data analysis assignment, when comparing AI with a human brain, it is clear that humans have a superior capacity for thought and, depending on the specifics of the issue at hand, superior problem-solving abilities.
While AI may improve with experience and training, it will never be as intelligent as a human being. While AI-driven systems excel at a select set of activities, it may take years for them to master a whole new set of capabilities in a different domain of use.
Task 4.2 Ethical implication of using AI in the workplace
The goal of this ethical framework is to serve as a manual for the responsible use of AI in business settings. Employers need to know what AI means for their business and what ethical considerations must be made before introducing AI into the workplace. The following are some ethical factors mentioned in the data analysis assignmentthat an organisation must take into account:
- limit human autonomy and freedom;
- regulate human behaviour;
- worsen the gap between the affluent and the poor;
- have a negative impact on the environment; and
- restrict human rights.
Experts are divided on whether or not AI will eventually replace people in the workplace as swiftly as robots. This might be due to the fact that artificial intelligence (AI) in the workplace could lead people to become overworked. Some artificial intelligence systems, according to a recent New York Times story, may be able to do tasks far more quickly than people.
One of the ethical factors an employer should take into account when deploying AI in the workplace is the potential to limit human liberty and freedom. Humans may lose some of their independence and freedom as a consequence of AI being used in the job. Call centre workers, according to a Guardian report referred to for the data analysis assignment, may no longer take breaks while a "custodian" is not there.
The employer must think about these moral issues to guarantee that AI is used ethically in the workplace.
The potential for AI to be biased in the workplace is a fundamental ethical concern when thinking about its use there. Some persons or communities may be disproportionately affected by AI. Intelligent systems enable the creation of biased applications. Created purposefully or not, bias may go either way. It is said that "it is vital to set ethical rules for the development and use of AI to guarantee that AI is not used for discrimination" in the article "Ethical and Social Implications of Artificial Intelligence."
As per the data analysis assignment Artificial intelligence (AI) in the workplace may have both positive and bad effects on employees. The development of a "artificial workforce" using AI is one such application. This might be seen as a reaction to the widespread use of automated processes. Using this kind of AI may drastically cut down on the number of workers required to do the same tasks as before. In the article, it is said that "this may lead to the loss of employment or at the very least income for people who become redundant." When evaluating a potential AI solution, it is essential to think about how it will affect employees. Researches "should think about the future and probable ramifications of AI before commencing the development process," as the article "Ethical and Social Implications of Artificial Intelligence" puts it. This may reduce the risk of difficulties caused by AI at work.
An "ethics board" or "ethical code of conduct" is also mentioned in the article. For this reason, regulations are necessary to prevent the discriminatory or otherwise harmful use of AI in the workplace.
In addition, there is the possibility that AI will be used to "manipulate people." Synthesizing "a fake world that is recognised as true" is within the capabilities of AI. Both the political climate and the economy might be significantly impacted by this. This is why it is important to keep a close eye on the progress of AI while writing the data analysis assignment.
There will be an increase in demand for specialised education and training as a result of the introduction of AI into the working world. Misconceptions about what AI is and how it operates contribute significantly to the problems that develop when it is used. Businesses should be familiar with AI and its capabilities. In addition, they should learn how artificial intelligence may benefit their business and speed up the process of reaching their objectives.
References
Appendix
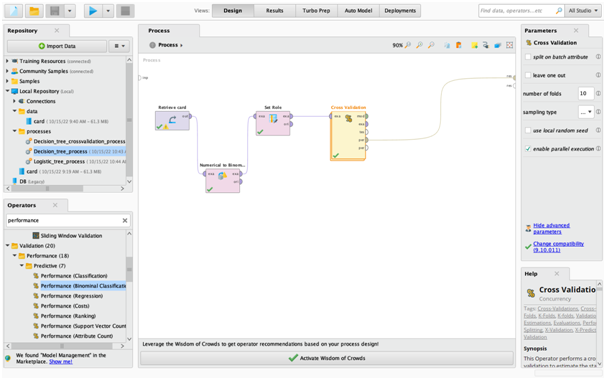
Appendix fig1: Decision Tree Cross Validation Process 1
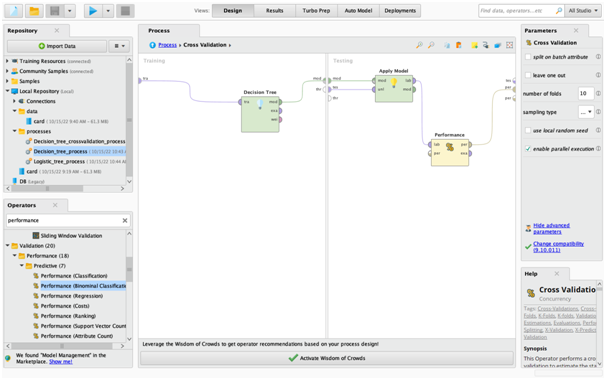
Appendix fig2: Decision Tree Cross Validation Process 2
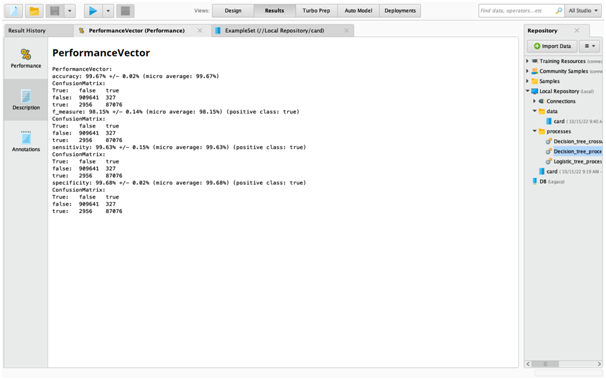
Appendix fig3: Decision Tree Cross Validation Output
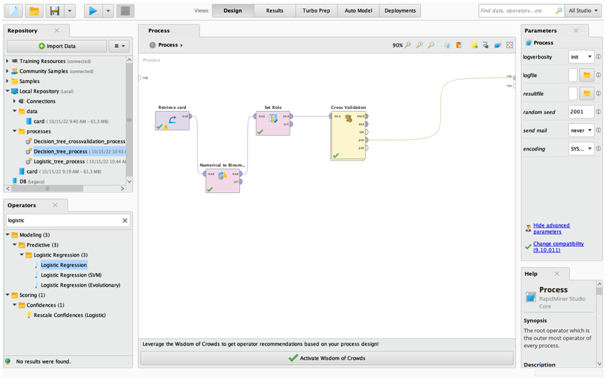
Appendix fig4: Logistic Regression Cross Validation Process1
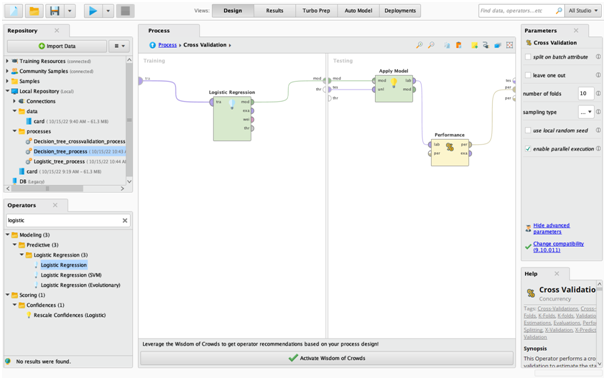
Appendix fig5: Logistic Regression Cross Validation Process 2
Appendix fig6: Logistic Regression Cross Validation Output